

But what is GPT-3?
A gentle intro to the most famous AI model of 2020

Hello Everyone 👋
Something amazing has happened last month in the world of AI, which got noticed by everyone in Tech world (and beyond) all over.
OpenAI released GPT-3. It seems to have several capabilities such as converting plain English text to code snippets (of multiple programming languages), translating legal documents to plain English and vice-versa, answer questions, and even write poetry (Mind=Blown! 🤯). With so many capabilities, the hype got too much that OpenAI CEO himself had to tweet this

So, what exactly is GPT-3? Let’s see
GPT-3 is something called as a Language Model. It is essentially a Deep Learning model, that is trained on a specific task - to predict next words in a sentence by looking at its previous words. The training data comes from an insanely big corpus - 45 TB of text from various public datasets such as Wikipedia and Reddit. So when it learns to predict next words from so many sentences, it essentially learns the hidden patterns in the text. It learns the grammatical constructs of the language such as various forms of the English words, how sentences are constructed etc. So these capabilities make GPT-3 as a language generation tool. It gets so good that it can write complete sentences, given some initial prompt. The trained model is again ridiculously big - with 175 billion parameters. But remember, it is trained essentially on internet data, which is not truly representative of legal documents or JavaScript code. So how does it work on these completely new tasks? The answer lies in Transfer Learning.
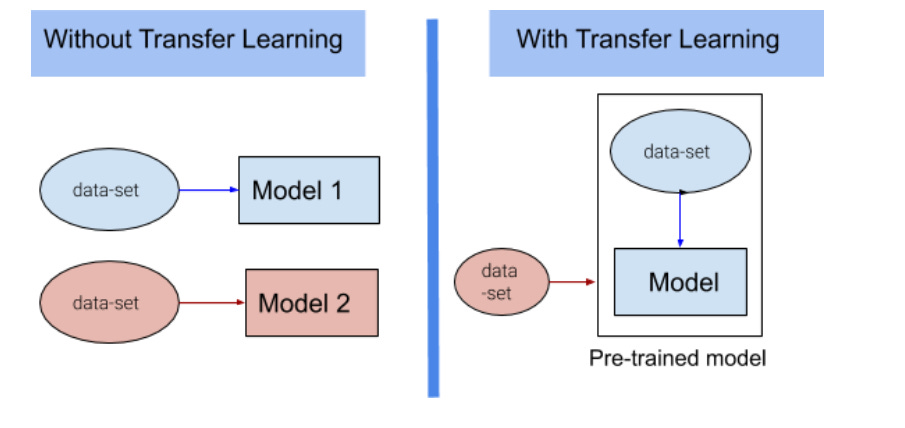
(Image and more on Transfer Learning)
While GPT-3 is super new, it is not really a breakthrough innovation. The stepping stones for this can be traced back to 2018, when two models ELMo and ULM-Fit were released. These models showed something ground-breaking. A model that is trained on one dataset, can be fine-tuned on a completely new dataset with much lesser data requirement and training requirement. This concept is called as Transfer Learning, and is built on idea that whether it is legal document or plain English, there are several characteristics common in the language. These patterns are learnt in the original training, and then such model can be fine-tuned to a more domain specific task.
Okay, does this make developers (and other jobs like writing creative content) obsolete? I don’t think so 👎. Atleast not in the near future. There are a couple of reasons for this:
Training and maintaining GPT-3 is very very difficult. It is estimated to have a memory requriement of 350 GB just to store the model, and the training cost was estimated to be around $12 million. So it is beyond reach for nearly any organization (except if you are Google or Microsoft) to afford replicating such a model.
So you need to rely on OpenAI’s API to use the model (which btw, is the only way to access it so far as they didn’t release the model to public). You still need to fine-tune the model to your requirements. This still requires significant expertise in handling text data.
The claims so far are still not really verifiable because the API is behind an invite only system so far and we don’t know exactly how well the model works in various cases. Infact I believe the closed system is also responsible for some of the hype. For all the great examples in public, there are also examples where the generated text loses coherence over long sentences
Because the model is trained on internet, and people are so so fair on internet (insert HUGE sarcasm sign), the model is prone to racial and gender biases. These might be big hurdles for adapting the model into many products. Imagine some racial statement on a product listing page on Amazon!! 😱
Most important reason - being a developer is not really about writing a few lines of code. It is about designing a system, planning the code architecture, writing test cases, identifying edge cases, optimizing for efficiency, readability, maintainability, integrating your code with various systems, deploying, and much more. So writing a code module is only a very small part of what a developer does.
If GPT-3 or its later successors do infact prove their mettle and displace some of the current jobs, I foresee these creating different kind of jobs such as:
Fine-tuning the models for your use-cases
Maintaining the infra required to support such models
Using such models as tools to get your tasks done. For example, instead of writing code, you can use tools such as Excel or Tableau to get various answers. So it may create many low-skill jobs as well, which require you to instruct the model, get its output, and then test for correctness, check edge cases etc.
Do you think GPT-3 is a threat to our jobs, or will it create more opportunities? Do let me know your thoughts.
If you like what you read, do share it with your friends.
If you haven’t already, subscribe to my newsletter for more such content 👇